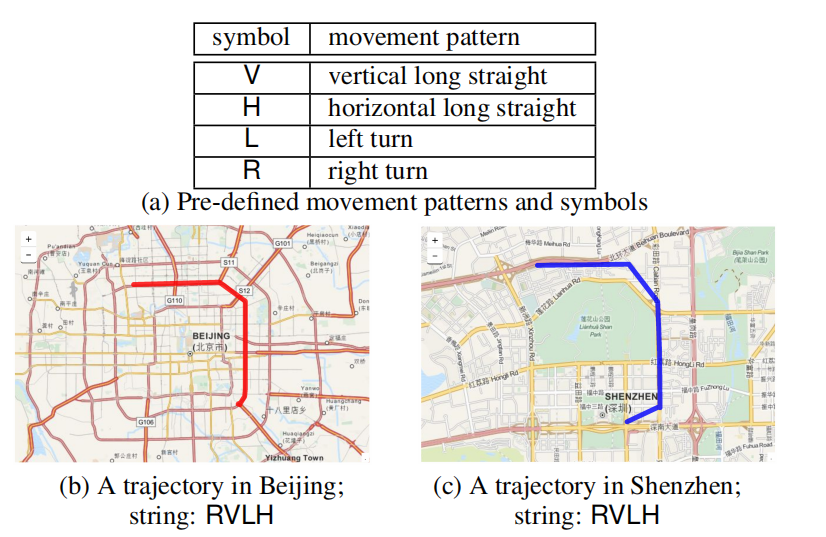
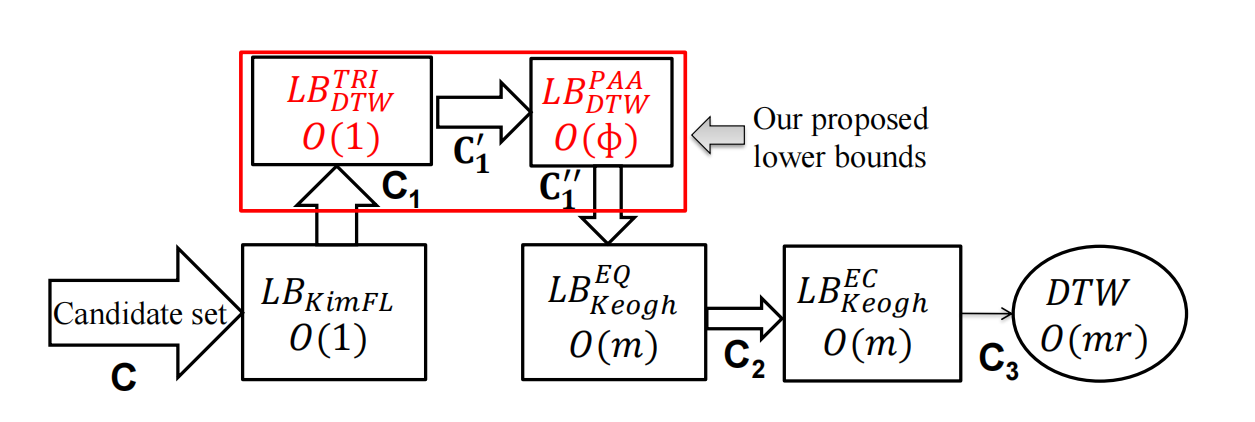
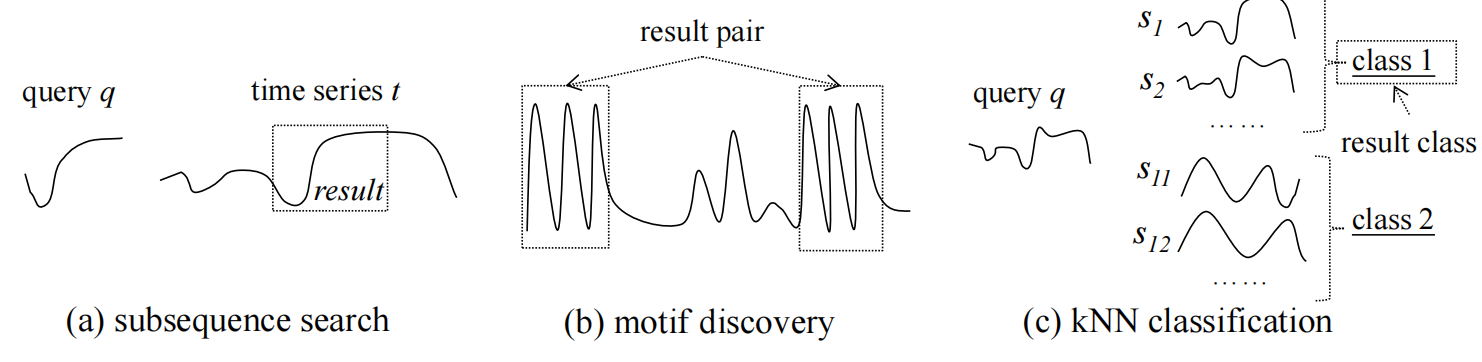
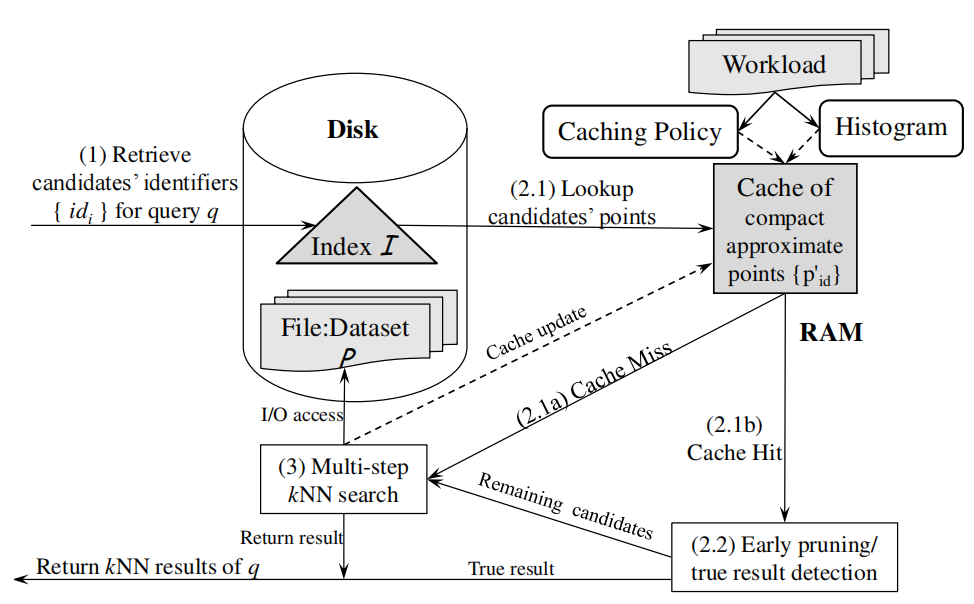
2025

AlayaDB: The Data Foundation for Efficient and Effective Long-context LLM Inference
Proceedings of the ACM on Management of Data (SIGMOD, CCF-A), 2025
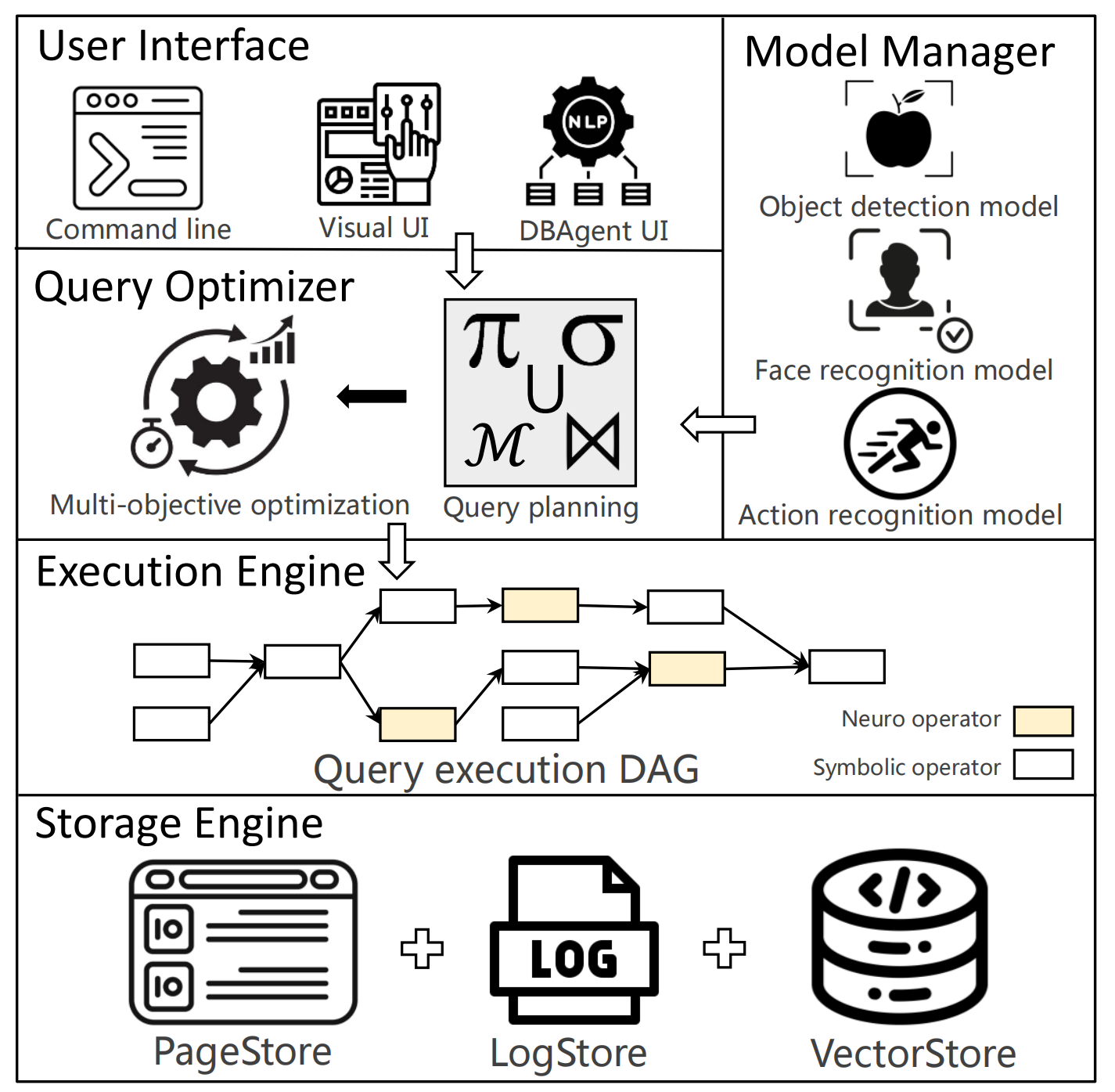
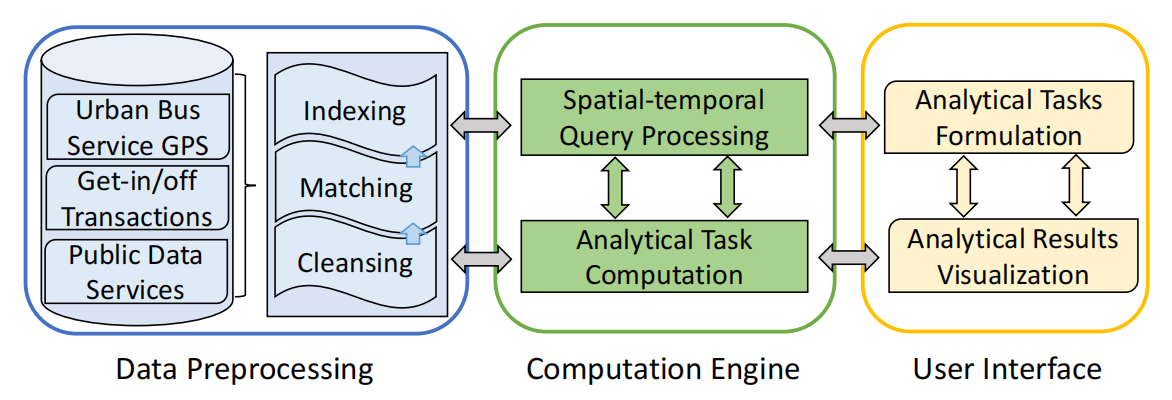
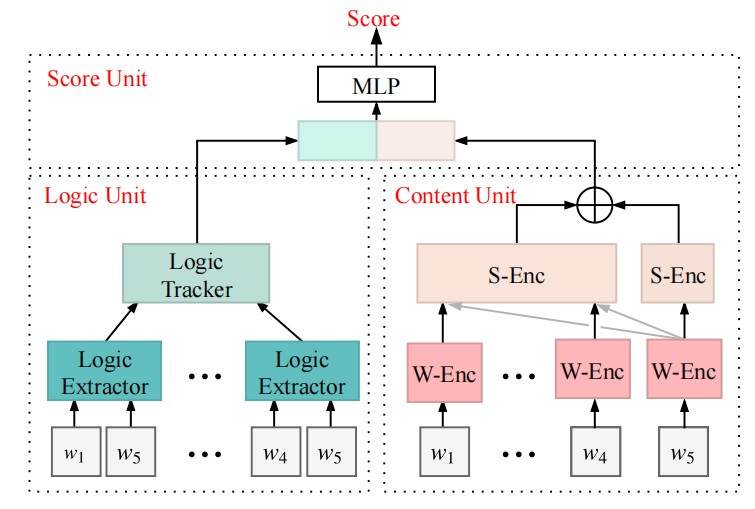
AlayaDB is a cutting-edge vector database system natively architected for efficient and effective long-context inference for Large Language Models (LLMs) at AlayaDB AI. Specifically, it decouples the KV cache and attention computation from the LLM inference systems, and encapsulates them into a novel vector database system. For the Model as a Service providers (MaaS), AlayaDB consumes fewer hardware resources and offers higher generation quality for various workloads with different kinds of Service Level Objectives (SLOs), when comparing with the existing alternative solutions (e.g., KV cache disaggregation, retrieval-based sparse attention). The crux of AlayaDB is that it abstracts the attention computation and cache management for LLM inference into a query processing procedure, and optimizes the performance via a native query optimizer. In this work, we demonstrate the effectiveness of AlayaDB via (i) three use cases from our industry partners, and (ii) extensive experimental results on LLM inference benchmarks.
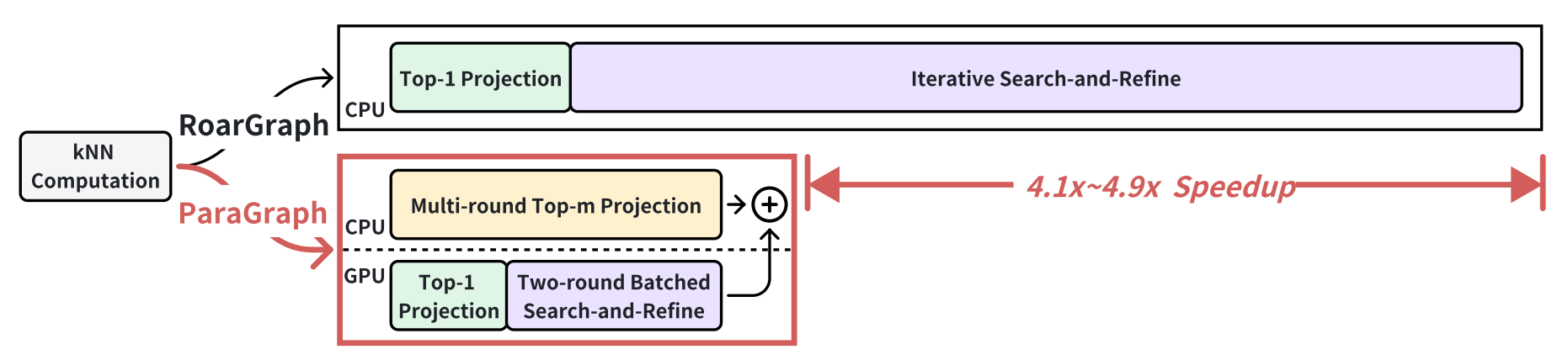
ParaGraph: Accelerating Graph Indexing through GPU-CPU Parallel Processing for Efficient Cross-modal ANNS
Data Management on New Hardware @ SIGMOD (DaMoN, CCF-A), 2025
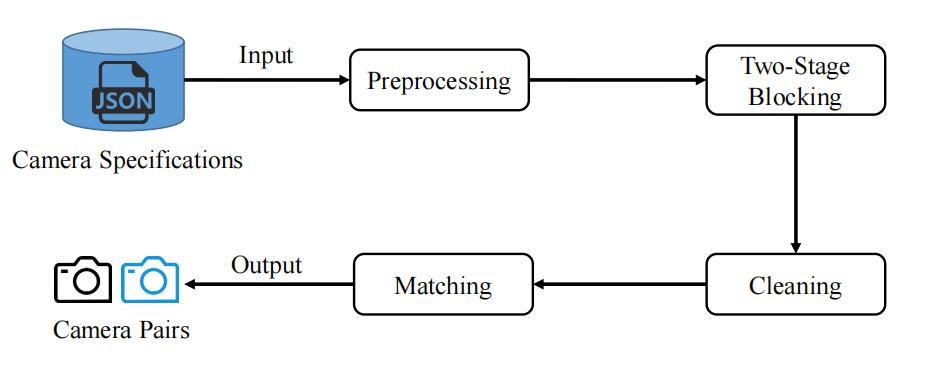
Cross-modal Approximate Nearest Neighbor Search (ANNS) is crucial for a growing number of applications, including search enginesand recommendation systems. However, existing vector search indexes often struggle with either poor search efficiency or slow index construction when handling cross-modal ANNS queries. To overcome these limitations, we introduce ParaGraph, a CPU-GPU co-processing system that enhances both search efficiency and construction speed for cross-modal ANNS. ParaGraph employs novel multi-round top-m projection and batched search-and-refine techniques for index construction. Additionally, it leverages modern heterogeneous hardware architectures by distributing computationally distinct tasks across the GPU and CPU, augmented with in-depth optimizations to maximize parallelism and performance. Compared to the state-of-the-art cross-modal ANNS index, ParaGraph achieves a 4.1× to 4.9× speedup in index construction and a 50% reduction in index size, while maintaining search efficiency.
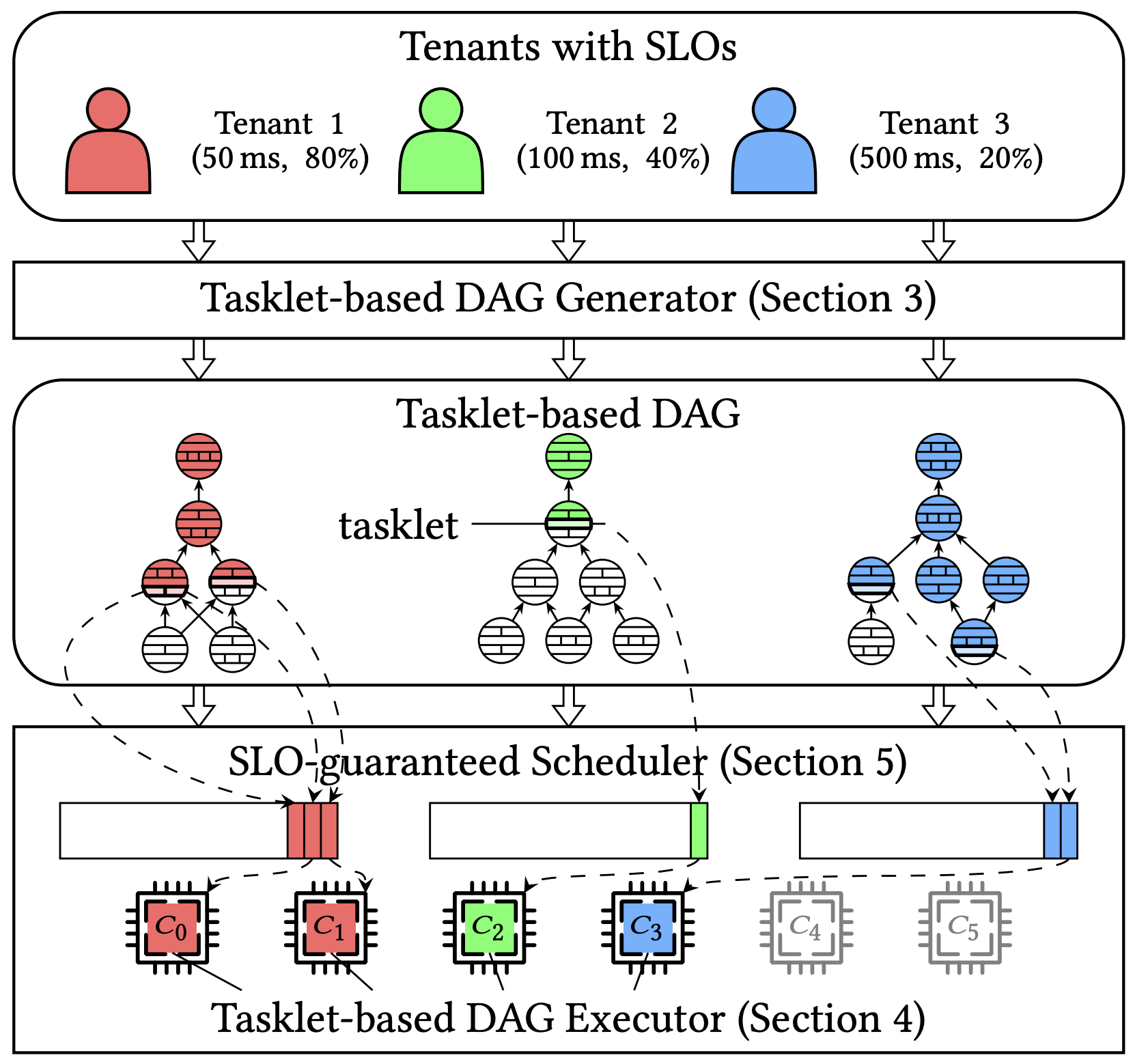
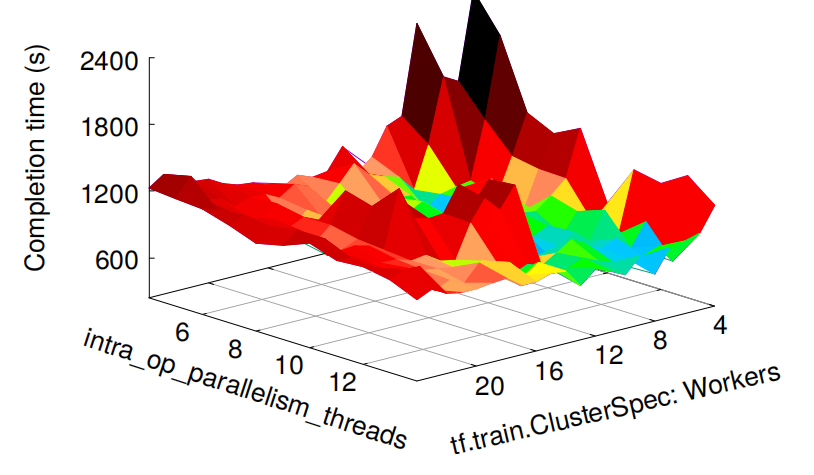
Tao: Improving Resource Utilization while Guaranteeing SLO in Multi-tenant Relational Database-as-a-Service
Proceedings of the ACM on Management of Data (SIGMOD, CCF-A), 2025
It is an open challenge for cloud database service providers to guarantee tenants' service-level objectives (SLOs) and enjoy high resource utilization simultaneously. In this work, we propose a novel system Tao to overcome it. Tao consists of three key components: (i) tasklet-based DAG generator, (ii) tasklet-based DAG executor, and (iii) SLO-guaranteed scheduler. The core concept in Tao is tasklet, a coroutine-based lightweight execution unit of the physical execution plan. In particular, we first convert each SQL operator in the traditional physical execution plan into a set of fine-grained tasklets by the tasklet-based DAG generator. Then, we abstract the tasklet-based DAG execution procedure and implement the tasklet-based DAG executor using C++20 coroutines. Finally, we introduce the SLO-guaranteed scheduler for scheduling tenants' tasklets across CPU cores. This scheduler guarantees tenants' SLOs with a token bucket model and improves resource utilization with an on-demand core adjustment strategy. We build Tao on an open-sourced relational database, Hyrise, and conduct extensive experimental studies to demonstrate its superiority over existing solutions.
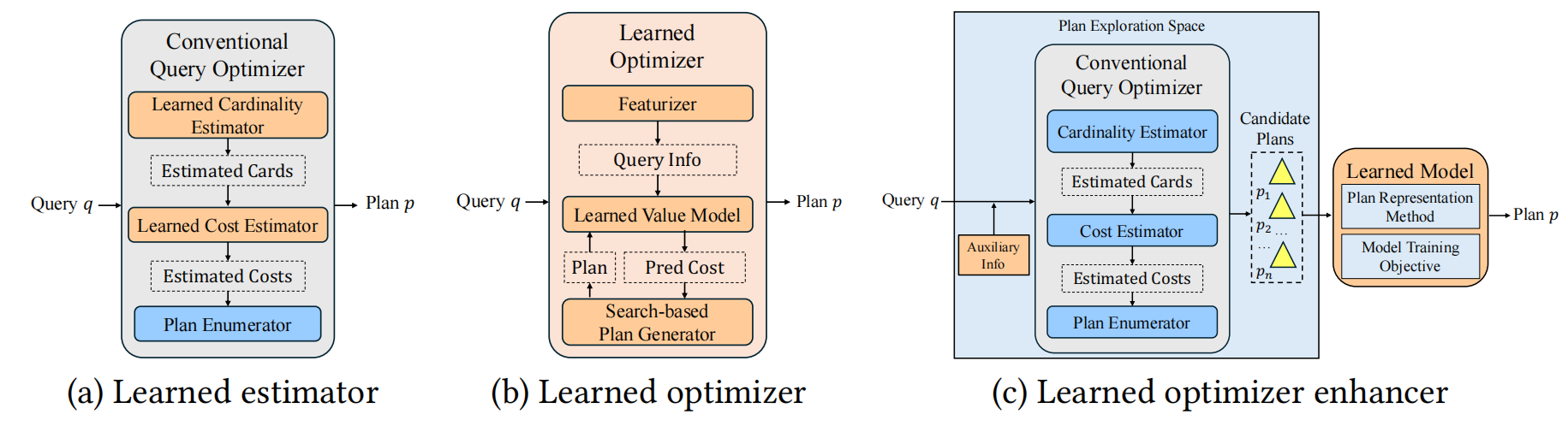
Athena: An Effective Learning-based Framework for Query Optimizer Performance Improvement
Proceedings of the ACM on Management of Data (SIGMOD, CCF-A), 2025
Recent studies have made it possible to integrate learning techniques into database systems for practical utilization. In particular, the state-of-the-art studies hook the conventional query optimizer to explore multiple execution plan candidates, then choose the optimal one with a learned model. This framework simplifies the integration of learning techniques into the database system. However, these methods still have room for improvement due to their limited plan exploration space and ineffective learning from execution plans. In this work, we propose Athena, an effective learning-based framework of query optimizer enhancer. It consists of three key components: (i) an order-centric plan explorer, (ii) a Tree-Mamba plan comparator and (iii) a time-weighted loss function. We implement Athena on top of the open-source database PostgreSQL and demonstrate its superiority via extensive experiments. Specifically, We achieve 1.75x, 1.95x, 5.69x, and 2.74x speedups over the vanilla PostgreSQL on the JOB, STATS-CEB, TPC-DS, and DSB benchmarks, respectively. Athena is 1.74x, 1.87x, 1.66x, and 2.28x faster than the state-of-the-art competitor Lero on these benchmarks. Additionally, Athena is open-sourced and it can be easily adapted to other relational database systems as all these proposed techniques in Athena are generic.
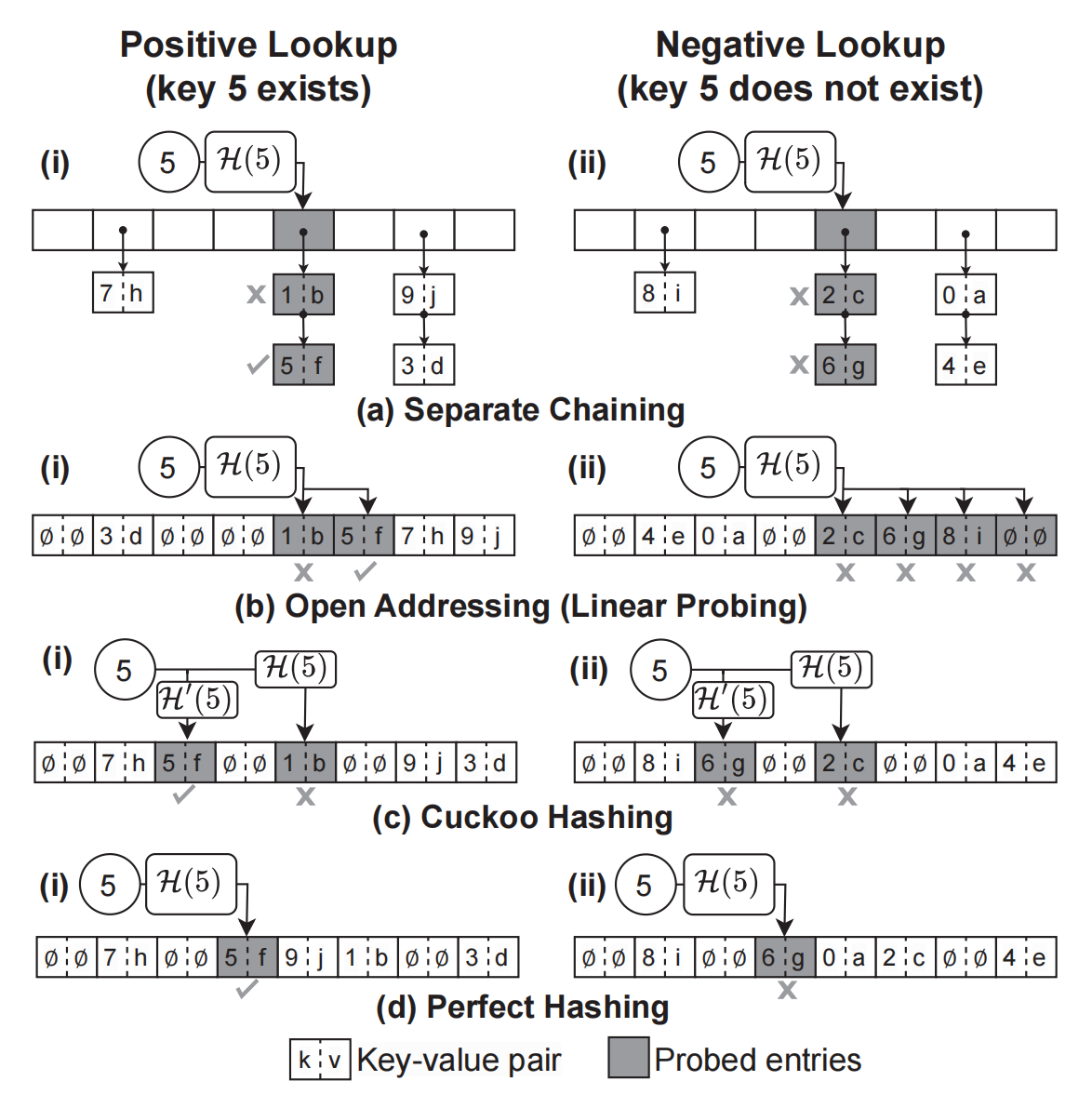
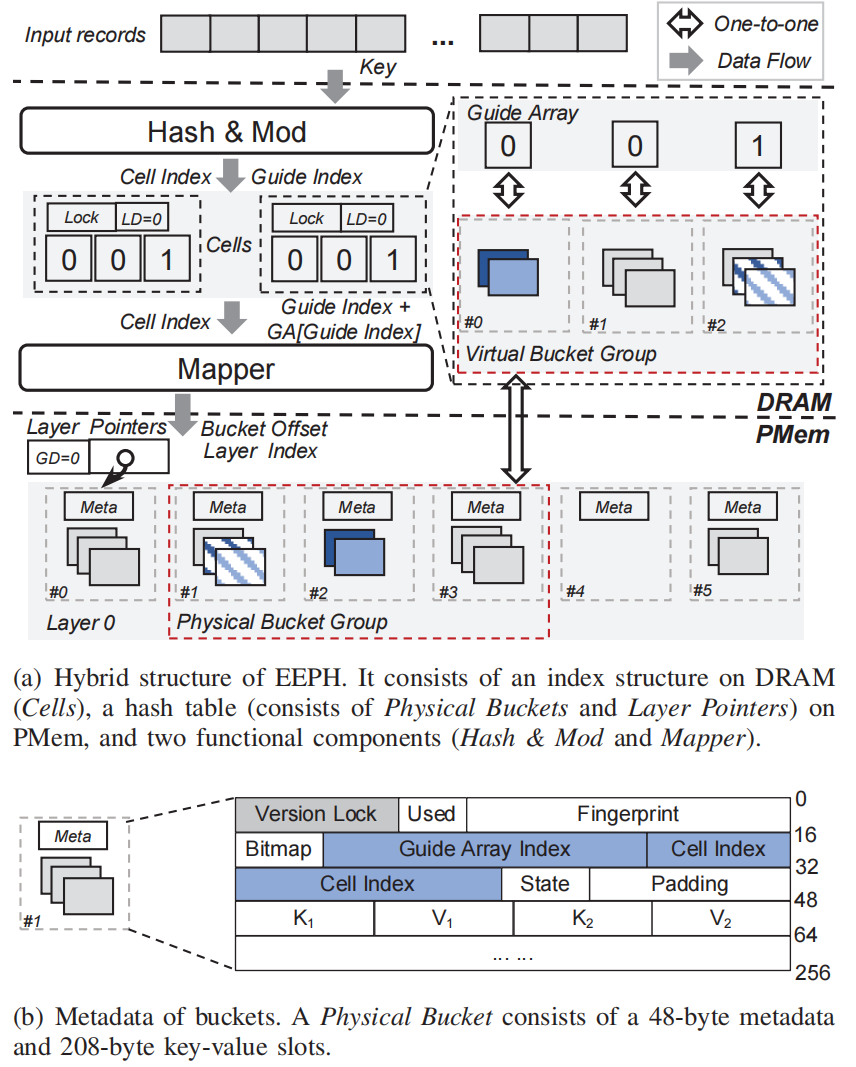
GPH: An Efficient and Effective Perfect Hashing Scheme for GPU Architecture
Proceedings of the ACM on Management of Data (SIGMOD, CCF-A), 2025
Hash tables are widely used to support fast lookup operations for various applications on key-value stores and relational databases. In recent years, hash tables have been significantly improved by utilizing the high memory bandwidth and large parallelism degree offered by Graphics Processing Units (GPUs). However, there is still a lack of comprehensive analysis of the lookup performance on existing GPU-based hash tables. In this work, we develop a micro-benchmark and devise an effective and general performance analysis model, which enables uniform and accurate lookup performance evaluation of GPU-based hash tables. Moreover, we propose GPH, a novel GPU-based hash table, to improve lookup performance with the guidance of the benchmark results from the analysis model devised above. In particular, GPH employs the perfect hashing scheme that ensures exactly 1 bucket probe for every lookup operation. Besides, we optimize the bucket requests to global memory in GPH by devising vectorization and instruction-level parallelism techniques. We also introduce the insert kernel in GPH to support dynamic updates (e.g., processing insert operations) on GPU. Experimentally, GPH achieves over 8500 million operations per second (MOPS) for lookup operation processing in both synthetic and real-world workloads, which outperforms all evaluated GPU-based hash tables.
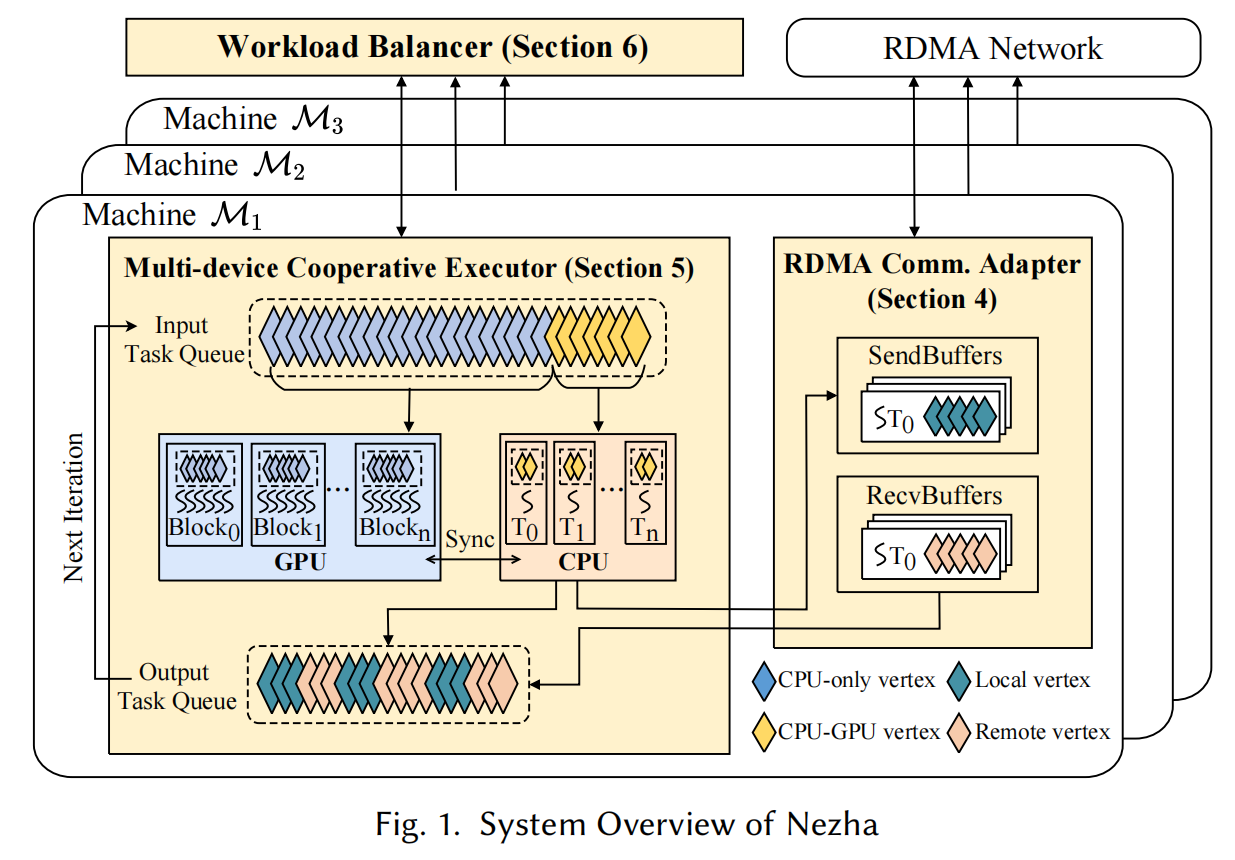
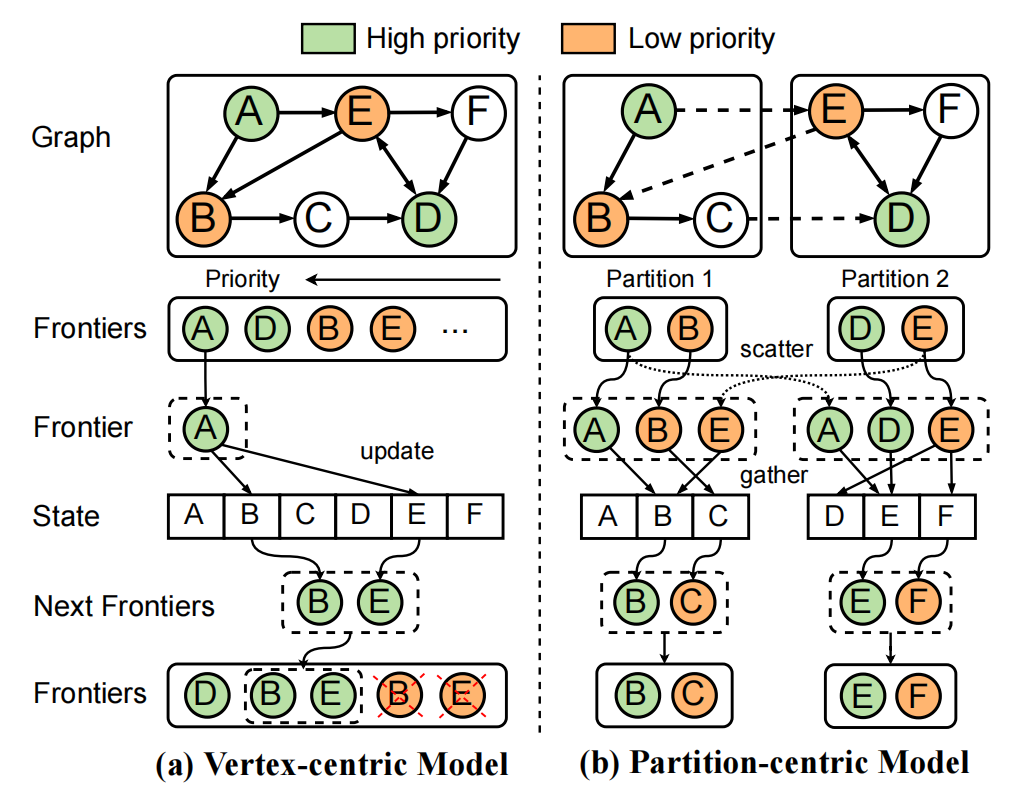
Nezha: An Efficient Distributed Graph Processing System on Heterogeneous Hardware
Proceedings of the ACM on Management of Data (SIGMOD, CCF-A), 2025
The growing scale of graph data across various applications demands efficient distributed graph processing systems. Despite the widespread use of the Scatter-Gather model for large-scale graph processing across distributed machines, the performance still can be significantly improved as the computation ability of each machine is not fully utilized and the communication costs during graph processing are expensive in the distributed environment. In this work, we propose a novel and efficient distributed graph processing system Nezha on heterogeneous hardware, where each machine is equipped with both CPU and GPU processors and all these machines in the distributed cluster are interconnected via Remote Direct Memory Access (RDMA). To reduce the communication costs, we devise an effective communication mode with a graphfriendly communication protocol in the graph-based RDMA communication adapter of Nezha. To improve the computation efficiency, we propose a multi-device cooperative execution mechanism in Nezha, which fully utilizes the CPU and GPU processors of each machine in the distributed cluster. We also alleviate the workload imbalance issue at inter-machine and intra-machine levels via the proposed workload balancer in Nezha. We conduct extensive experiments by running 4 widely-used graph algorithms on 5 graph datasets to demonstrate the superiority of Nezha over existing systems.
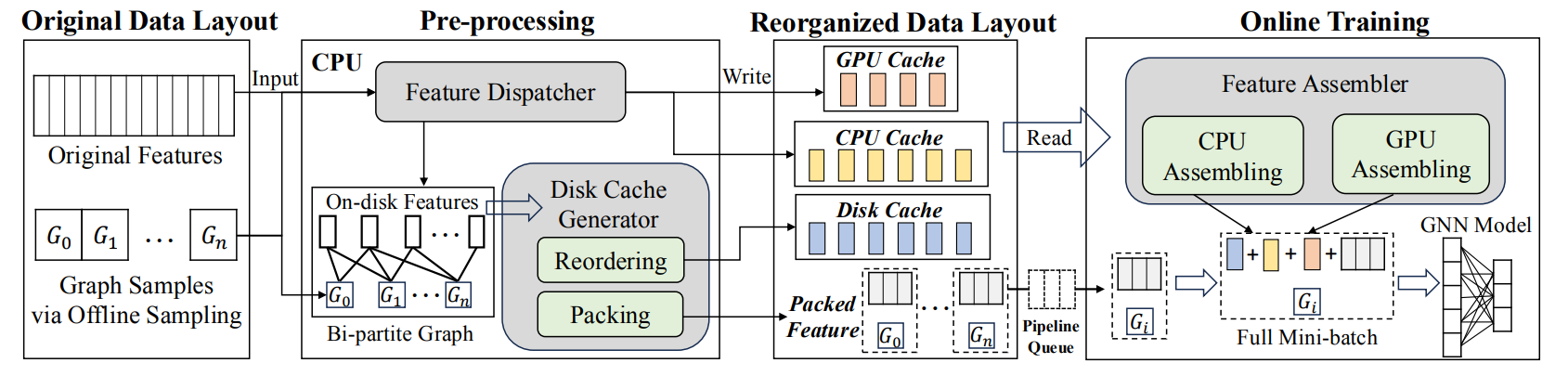
DiskGNN: Bridging I/O Efficiency and Model Accuracy for Out-of-Core GNN Training
Proceedings of the ACM on Management of Data (SIGMOD, CCF-A), 2025
Graph neural networks (GNNs) are models specialized for graph data and widely used in applications. To train GNNs on large graphs that exceed CPU memory, several systems have been designed to store data on disk and conduct out-of-core processing. However, these systems suffer from either read amplification when conducting random reads for node features that are smaller than a disk page, or degraded model accuracy by treating the graph as disconnected partitions. To close this gap, we build DiskGNN for high I/O efficiency and fast training without model accuracy degradation. The key technique is offline sampling, which decouples graph sampling from model computation. In particular, by conducting graph sampling beforehand for multiple mini-batches, DiskGNN acquires the node features that will be accessed during model computation and conducts pre-processing to pack the node features of each mini-batch contiguously on disk to avoid read amplification for computation. Given the feature access information acquired by offline sampling, DiskGNN also adopts designs including four-level feature store to fully utilize the memory hierarchy of GPU and CPU to cache hot node features and reduce disk access, batched packing to accelerate feature packing during pre-processing, and pipelined training to overlap disk access with other operations. We compare DiskGNN with state-of-the-art out-of-core GNN training systems. The results show that DiskGNN has more than 8× speedup over existing systems while matching their best model accuracy. DiskGNN is open-source at https://github.com/Liu-rj/DiskGNN.
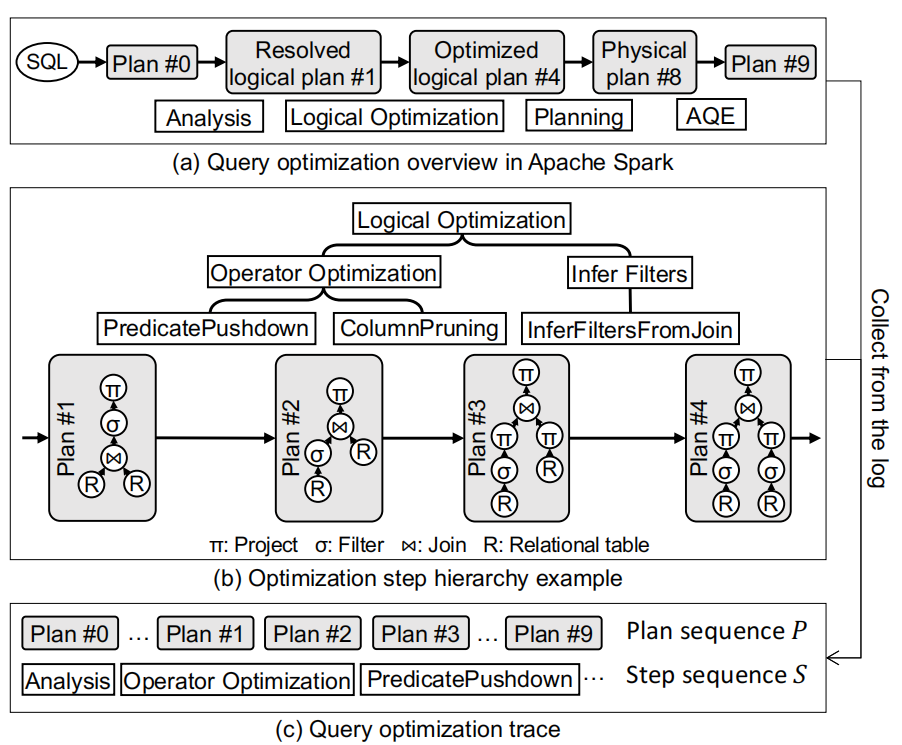
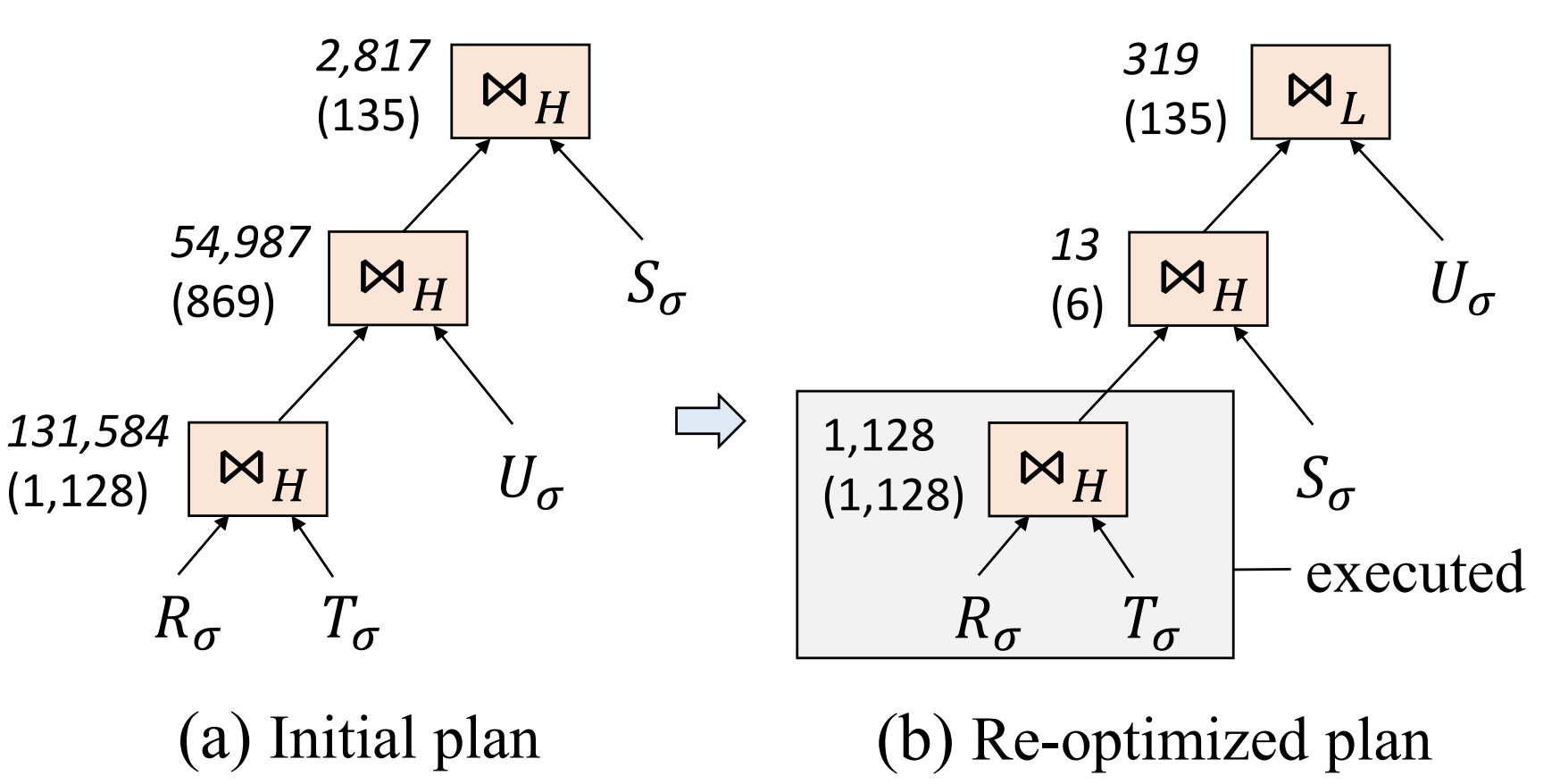
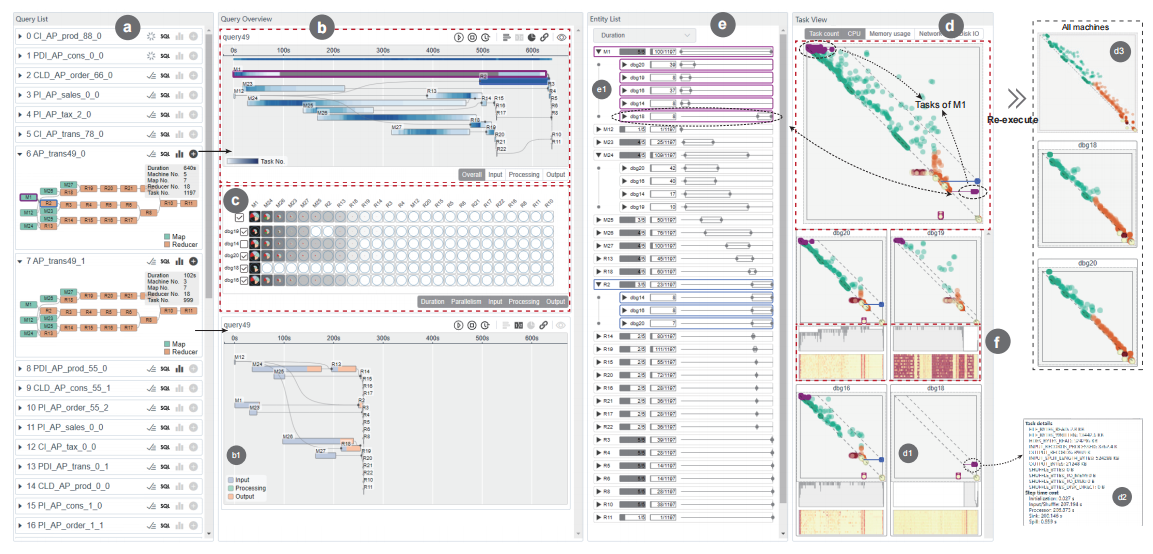
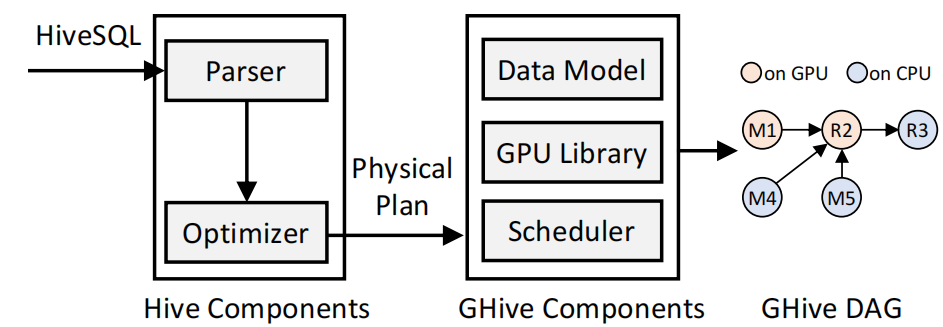
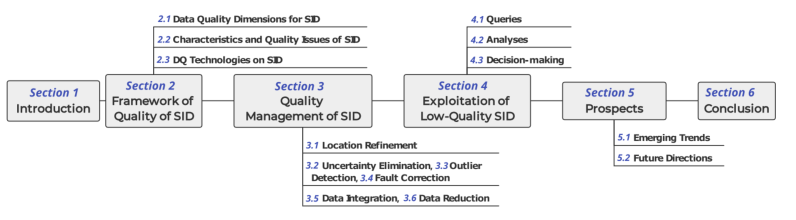
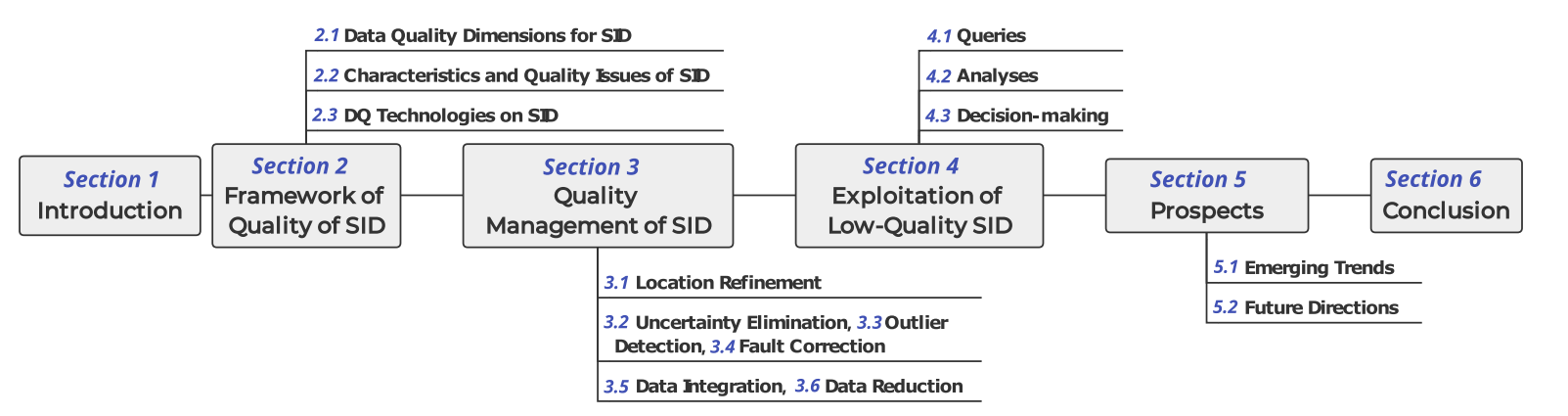
QOVIS: Understanding and Diagnosing Query Optimizer via a Visualization-assisted Approach
Proceedings of the VLDB Endowment (PVLDB, CCF-A), 2025
Understanding and diagnosing query optimizers is crucial to guar antee the correctness and efficiency of query processing in database systems. However, achieving this is non-trivial as there are three technical challenges: (i) hundreds and thousands of query plans are generated for each query during the query optimization proce dure; (ii) the transformation logic among query plans is not easy to investigate even for expert database system developers; and (iii) navigating users to the root causes of the bugs/errors is in herently hard as the changes of the operators among query plans are missing in the query processing log. In this work, we propose QOVIS to overcome these challenges, which identifies the query optimization bugs/issues and investigates their root causes via a visualization-assisted approach. Specifically, QOVIS consists of data preprocessing layer, transformation logic computation layer, and visual analysis layer. We conduct extensive experimental studies (e.g., user study, case study, and performance study) to evaluate the efficiency and effectiveness of QOVIS. In particular, our user study (on 24 database developers and researchers) confirms that QOVIS significantly reduces the time required to investigate the bugs/er rors in the query optimizer. Moreover, the generality of QOVIS is verified by utilizing it to understand and diagnose the real-world reported bugs/errors in different query optimizers of three widely used systems: Apache Spark, Apache Hive, and DuckDB
Efficient and Effective Algorithms for A Family of Influence Maximization Problems with A Matroid Constraint
Proceedings of the VLDB Endowment (PVLDB, CCF-A), 2025
Influence maximization (IM) is a classic problem that aims to identify a small group of critical individuals, known as seeds, who can influence the largest number of users in a social network through word-of-mouth. This problem finds important applications including viral marketing, infection detection, and misinformation containment. The conventional IM problem is typically studied with the oversimplified goal of selecting a single seed set. Many realworld scenarios call for multiple sets of seeds, particularly on social media platforms where various viral marketing campaigns need different sets of seeds to propagate effectively. To this end, previous works have formulated various IM variants, central to which is the requirement of multiple seed sets, naturally modeled as a matroid constraint. However, the current best-known solutions for these variants either offer a weak (1/2 − 𝜖)-approximation, or offer a (1 − 1/𝑒 − 𝜖)-approximation algorithm that is very expensive. We propose an efficient seed selection method called AMP, an algorithm with a (1 − 1/𝑒 − 𝜖)-approximation guarantee for this family of IM variants. To further improve efficiency, we also devise a fast implementation, called RAMP. We extensively evaluate the performance of our proposal against 6 competitors across 4 IM variants and on 7 real-world networks, demonstrating that our proposal outperforms all competitors in terms of result quality, running time, and memory usage. We have also deployed RAMP in a real industry strength application involving online gaming, where we show that our deployed solution significantly improves upon the baselines