



The Database Research Group is founded in 2017 and affiliated to Department of Computer Science and Engineering, Southern University of Science and Technology. We conduct in-depth, interesting and insightful researches on data science and engineering, which cover the following aspects:
(1) System: Architect novel data-intensive systems from 0 to 1 (lead by Dr. Bo Tang); (2) Algorithm: Support and accelerate advanced data analytics (lead by Dr. Bo Tang); (3) VIS: Enable intuitive visual understanding of data and systems (lead by Dr. Qiaomu Shen); (4) AI: Improve data analytics and system performance with deep learning (lead by Dr. Dan Zeng).
System
Algorithm
VIS
AI
For more details about our researches, please refer to our publications. We always welcome brilliant people to join DBGroup.
2025-06
Our research group attended SIGMOD 2025 in Berlin, Germany, and presented 8 papers! This is a fantastic achievement, showcasing our team's significant contributions to data management. Congratulations to everyone involved!
2025-04
Our work "ParaGraph: Accelerating Cross-Modal ANNS Indexing via GPU-CPU Parallelism" got accepted to DaMoN 2025. Congratulations to Yuxiang and Bo, special thanks to AlayaDB Inc. for support!
2025-03
Our work "OptMatch: an Efficient and GenericNeural Network-assisted Subgraph Matching Approch" got accepted to ICDE 2025. Congratulations to Wenzhe and Bo
2025-03
We open-sourced the lightweight vector database "AlayaLite", open source address: https://github.com/AlayaDB-AI/AlayaLite. Congratulations to the core development team!
2025-03
Our work "VQLens: A Demonstration of Vector Query Execution Analysis" got accepted to SIGMOD 2025 demo track. Congratulations to Yansha and Bo.
Date
Title
Speaker
2025-03-24
Agent Program: Concepts & Practices
Renjie Liu, CS master student at DBGroup in Southern University of Science and Technology (SUSTech)
2025-03-10
Progressive Sparse Attention: Algorithm and System Co-design for Efficient Attention in LLM Serving
Peiqi Yin, Ph.D. candidate at The Chinese University of Hong Kong (CUHK)
2025-02-19
PALF: Replicated Write-Ahead Logging for Distributed Databases
徐泉清,北京大学计算机系博士毕业、正高级工程师、蚂蚁技术研究院数据库实验室研究员

AlayaDB: The Data Foundation for Efficient and Effective Long-context LLM Inference
Proceedings of the ACM on Management of Data (SIGMOD, CCF-A), 2025
AlayaDB is a cutting-edge vector database system natively architected for efficient and effective long-context inference for Large Language Models (LLMs) at AlayaDB AI. Specifically, it decouples the KV cache and attention computation from the LLM inference systems, and encapsulates them into a novel vector database system. For the Model as a Service providers (MaaS), AlayaDB consumes fewer hardware resources and offers higher generation quality for various workloads with different kinds of Service Level Objectives (SLOs), when comparing with the existing alternative solutions (e.g., KV cache disaggregation, retrieval-based sparse attention). The crux of AlayaDB is that it abstracts the attention computation and cache management for LLM inference into a query processing procedure, and optimizes the performance via a native query optimizer. In this work, we demonstrate the effectiveness of AlayaDB via (i) three use cases from our industry partners, and (ii) extensive experimental results on LLM inference benchmarks.
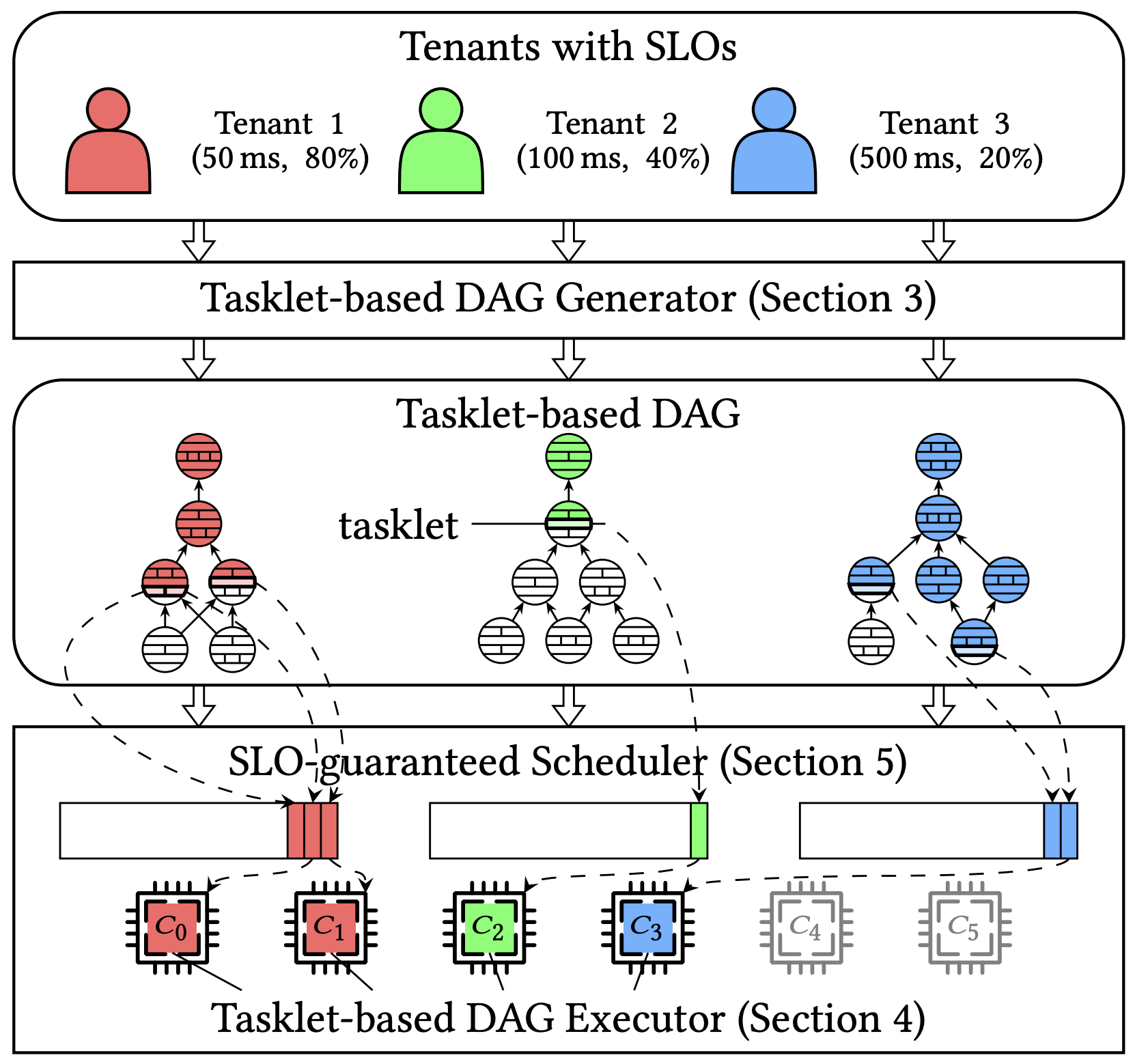
Tao: Improving Resource Utilization while Guaranteeing SLO in Multi-tenant Relational Database-as-a-Service
Proceedings of the ACM on Management of Data (SIGMOD, CCF-A), 2025
It is an open challenge for cloud database service providers to guarantee tenants' service-level objectives (SLOs) and enjoy high resource utilization simultaneously. In this work, we propose a novel system Tao to overcome it. Tao consists of three key components: (i) tasklet-based DAG generator, (ii) tasklet-based DAG executor, and (iii) SLO-guaranteed scheduler. The core concept in Tao is tasklet, a coroutine-based lightweight execution unit of the physical execution plan. In particular, we first convert each SQL operator in the traditional physical execution plan into a set of fine-grained tasklets by the tasklet-based DAG generator. Then, we abstract the tasklet-based DAG execution procedure and implement the tasklet-based DAG executor using C++20 coroutines. Finally, we introduce the SLO-guaranteed scheduler for scheduling tenants' tasklets across CPU cores. This scheduler guarantees tenants' SLOs with a token bucket model and improves resource utilization with an on-demand core adjustment strategy. We build Tao on an open-sourced relational database, Hyrise, and conduct extensive experimental studies to demonstrate its superiority over existing solutions.
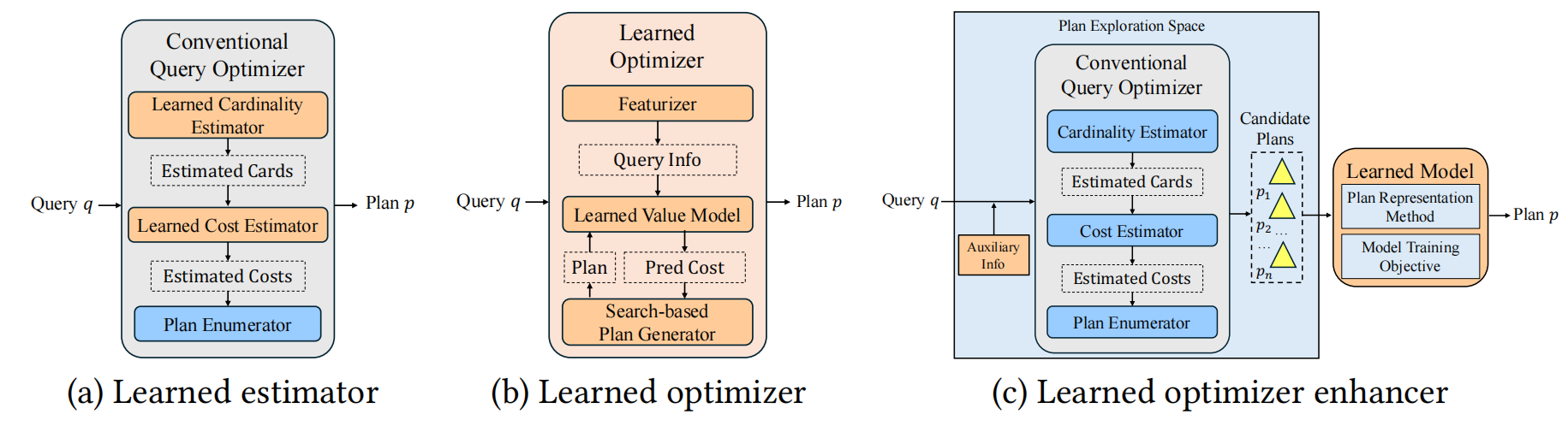
Athena: An Effective Learning-based Framework for Query Optimizer Performance Improvement
Proceedings of the ACM on Management of Data (SIGMOD, CCF-A), 2025
Recent studies have made it possible to integrate learning techniques into database systems for practical utilization. In particular, the state-of-the-art studies hook the conventional query optimizer to explore multiple execution plan candidates, then choose the optimal one with a learned model. This framework simplifies the integration of learning techniques into the database system. However, these methods still have room for improvement due to their limited plan exploration space and ineffective learning from execution plans. In this work, we propose Athena, an effective learning-based framework of query optimizer enhancer. It consists of three key components: (i) an order-centric plan explorer, (ii) a Tree-Mamba plan comparator and (iii) a time-weighted loss function. We implement Athena on top of the open-source database PostgreSQL and demonstrate its superiority via extensive experiments. Specifically, We achieve 1.75x, 1.95x, 5.69x, and 2.74x speedups over the vanilla PostgreSQL on the JOB, STATS-CEB, TPC-DS, and DSB benchmarks, respectively. Athena is 1.74x, 1.87x, 1.66x, and 2.28x faster than the state-of-the-art competitor Lero on these benchmarks. Additionally, Athena is open-sourced and it can be easily adapted to other relational database systems as all these proposed techniques in Athena are generic.

Ph.D. Candidate
Class of 2019

Ph.D. Candidate
Class of 2020

Ph.D. Candidate
Class of 2020

Ph.D. Candidate
Class of 2021

Ph.D. Candidate
Class of 2021

Ph.D. Candidate
Class of 2021

Ph.D. Candidate
Class of 2021

Ph.D. Candidate
Class of 2022

Ph.D. Candidate
Class of 2022

MPhil Candidate
Class of 2019

MPhil Candidate
Class of 2020

MPhil Candidate
Class of 2020

MPhil Candidate
Class of 2021

MPhil Candidate
Class of 2021

MPhil Candidate
Class of 2021

MPhil Candidate
Class of 2022

MPhil Candidate
Class of 2022




We always welcome brilliant people to join our group. If you want to join DBGroup, please fill this form and drop an email to us as soon as possible.
dbgroup_AT_sustech_DOT_edu_DOT_cn
DBGroup, South Tower, CoE Building
Southern University of Science and Technology
Shenzhen, China



